본 글은 모두를 위한 R 데이터 분석 입문 책을 공부하면서 정리·요약한 내용입니다.
저자 : 오세종
출판 : 한빛아카데미
1. - 3 - 변주형 변수 X -> 연속형 변수 O
2. - 2 -
3. - 2 - 표본의 크기가 작아도 X
복습
1. 공공데이터 포털에서 올레코스 현황 데이터를 검색하여 다운로드 받은 후 jeju.csv로 이름을 변경하시오. (C:/source에 저장)
setwd("C:/Source")
2. R에서 jeju.csv를 읽어서 jeju로 저장하시오.
jeju <- read.csv('jeju.csv', header=T)
3. 열 이름을 다음과 같이 변경하시오. names(jeju) <- c("course","course_name","km","time","start_end","date")
names(jeju) <- c("course","course_name","km","time","start_end","date")
4. str, head, summary로 확인하시오.
str(jeju)
head(jeju)
summary(jeju)
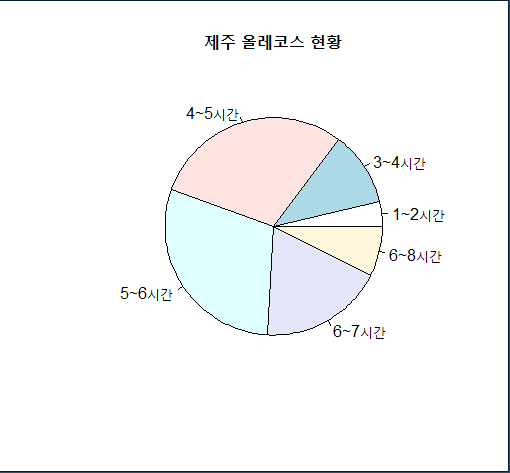
5. jeju$time으로 막대그래프와 원 그래프를 그리시오.
ds<-table(jeju$time)
barplot(ds, main="제주 올레코스 현황", col="blue") # 막대 그래프
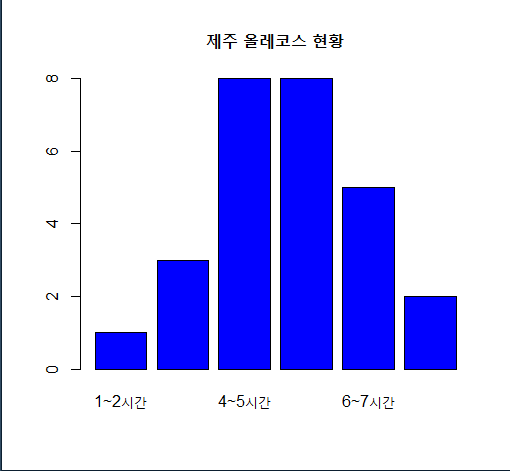
pie(ds, main="제주 올레코스 현황") # 원 그래프
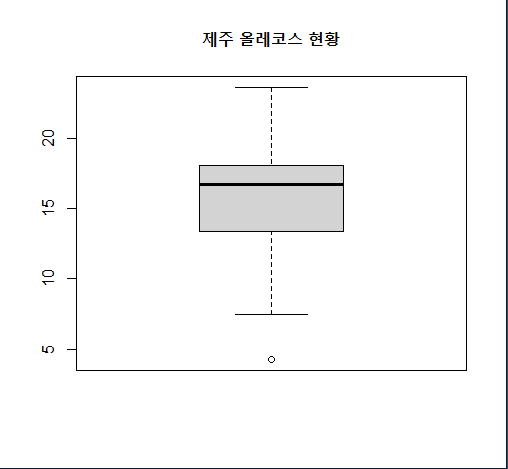
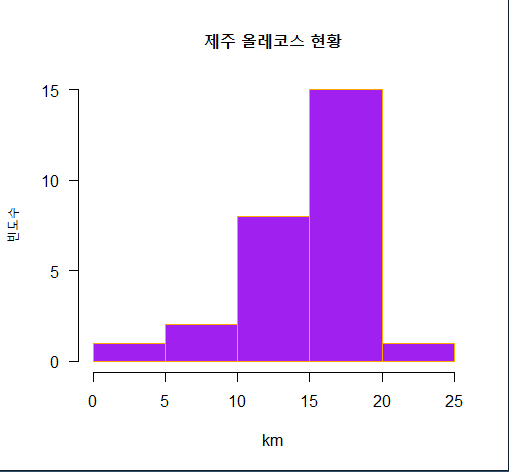
6. jeju$km로 상자그림과 히스토그램을 그리시오.
dist <- jeju$km
boxplot(dist, main="제주 올레코스 현황") # 상자그림
hist(dist, # 히스토그램
main="제주 올레코스 현황",
xlab="km",
ylab="빈도수",
border="orange",
col="purple",
las=1)
워드 클라우드 생성기
태그 클라우드 또는 워드 클라우드는 메타 데이터에서 얻어진 태그들을 분석하여 중요도나 인기도 등을 고려하여 시각적으로 늘어 놓아 웹 사이트에 표시하는 것
보통은 2차원의 표와 같은 형태로 태그들이 배치되며 이때 순서는 알파벳/가나다 순으로 배치

산점도
다중변수 자료(또는 다변량 자료): 변수가 2개 이상인 자료
다중변수 자료는 2차원 형태를 나타내며, 이는 매트릭스나 데이터 프레임에 저장하여 분석
산점도(scatter plot)란 2개의 변수로 구성된 자료의 분포를 알아보는 그래프
두 변수사이에 상관관계가 있는지 분석할 수 있음
두 변수 사이의 산점도 (mtcars$wt, mtcars$mpg)
? mtcars # mtcars 도움말
str(mtcars) # mtcars 요약
head(mtcars) # mtcars 앞부터 6개의 데이터
wt <- mtcars$wt # 중량 자료
mpg <- mtcars$mpg # 연비 자료
plot(wt, mpg, # 2개 변수(x축, y축)
main="중량-연비 그래프", # 제목
xlab="중량", # x축 레이블
ylab="연비(MPG)", # y축 레이블
col="red", # point의 color
pch=20) # point의 종류
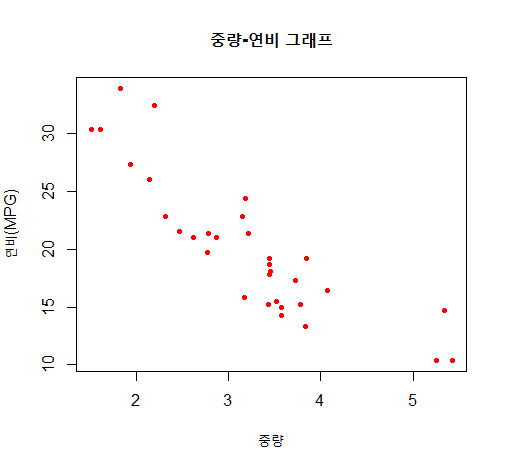
분석 결과 : 중량이 낮을수록 연비가 높다. (차가 무거울수록 연료 소모가 크다)
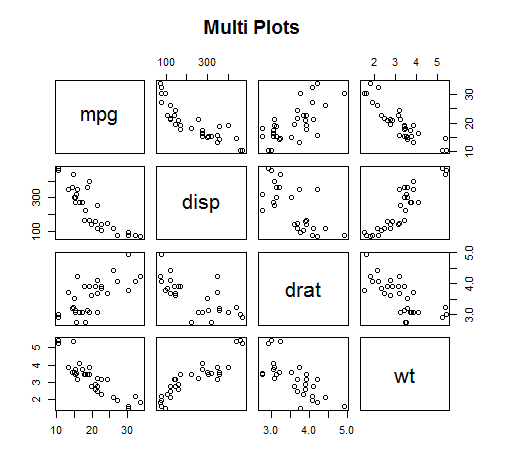
여러 변수들 간의 산점도
pairs() 함수 : 여러 개의 변수에 대해 짝지어진 산점도를 한 번에 그림
vars <- c("mpg", "disp", "drat", "wt") # 대상 변수
target <- mtcars[, vars]
head(target)
pairs(target, main="Multi Plots") # 대상 데이터
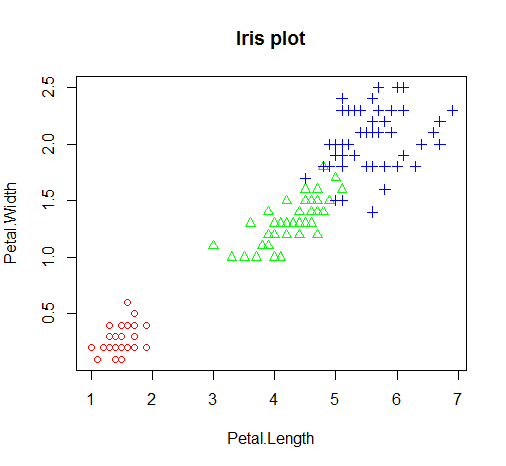
그룹 정보가 있는 두 변수의 산점도
그룹 정보를 알고 있다면 산점도를 작성 시 각 그룹별 관측값들을 다른 색깔과 점의 모양으로 표시할 수 있음
이렇게 작성된 산점도는 두 변수 간의 관계뿐만 아니라 그룹 간의 관계도 파악할 수 있어서 편리
iris.2 <- iris[,3:4] # 데이터 준비
iris.2
point <- as.numeric(iris$Species) # 점의 모양 (iris$Species를 숫자로 변환)
point # point 내용 출력
color <- c("red", "green", "blue") # 점의 컬러
plot(iris.2,
main="Iris plot",
pch=c(point),
col=color[point])
연습문제
1) R에서 제공하는 cars 데이터셋을 이용하여 속도(speed)와 제동거리(dist)에 대한 산점도를 작성하고, 두 변수 간의 상관관계를 설명하시오(x축: speed, y축: dist).
str(cars)
speed <- cars$speed
dist <- cars$dist
plot(speed, dist,
main="속도-제동거리 그래프",
xlab="속도",
ylab="제동거리",
col="red",
pch=20)
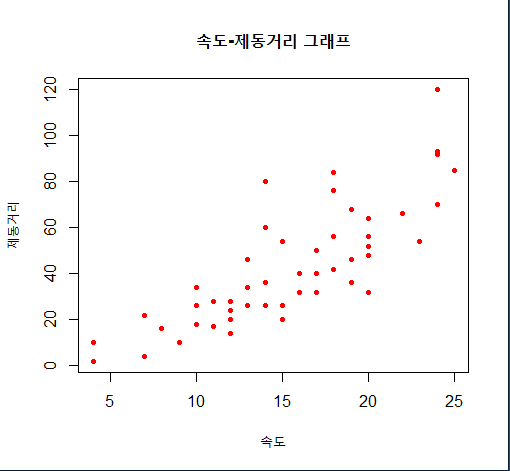
# 분석 결과 : 속도가 증가할수록 제동거리도 "선형적"으로 증가한다.
2) R에서 제공하는 pressure 데이터셋을 이용하여 온도(temperature)와 기압(pressure)에 대한 산점도를 작성하고, 두 변수 간의 상관관계를 설명하시오(x축: temperature, y축: pressure).
str(pressure)
temperature <- pressure$temperature
pressure <- pressure$pressure
plot(temperature, pressure,
main="온도-기압 그래프",
xlab="온도",
ylab="기압",
col="red",
pch=20)
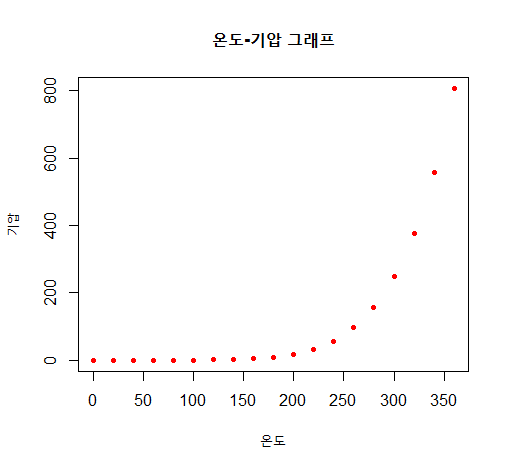
# 분석 결과 : 일정온도(200도)에서부터 기압이 "지수적"으로 증가한다.
상관분석과 상관계수
자동차의 중량이 커지면 연비는 감소하는 추세
추세의 모양이 선(線, line) 모양이어서 중량과 연비는 ‘선형적 관계’에 있다고 표현
선형적 관계라고 해도 강한 선형적 관계가 있고 약한 선형적 관계도 있음
상관분석(correlation analysis) : 얼마나 선형성을 보이는지 수치상으로 나타낼 수 있는 방법
피어슨 상관계수 (소문자 r로 표시)
r = 1 => /방향, r = -1 \방향
-1 ≤ r ≤ 1
r > 0 : 양의 상관관계(x가 증가하면 y도 증가)
r < 0 : 음의 상관관계(x가 증가하면 y는 감소)
r=0 : 상관관계 없음
r이 1이나 –1에 가까울수록 x, y의 상관성이 높음
회귀식 : 원인과 결과가 존재한다.
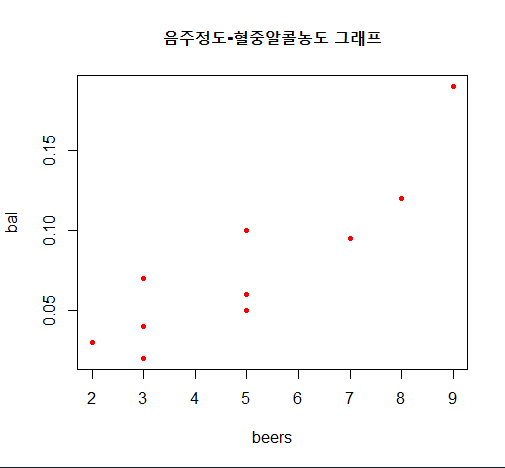
R을 이용한 상관계수의 계산 (음주정도와 혈중알콜농도가 상관성 조사)
beers <- c(5, 2, 9, 8, 3, 7, 3, 5, 3, 5) # beers 벡터 작성
bal <- c(0.10, 0.03, 0.19, 0.12, 0.04, 0.095, 0.07, 0.06, 0.02, 0.05) # bal 벡터 작성
tbl <- data.frame(beers, bal) # 데이터프레임 생성
plot(bal~beers, data=tbl, # ~ 사용 시 앞에것이 y축, 뒤에것이 x축
main="음주정도-혈중알콜농도 그래프",
col="red",
pch=20)
res<- lm(bal~beers, data=tbl) # 회귀식 도출, ~ : (앞 y축 ~ 뒤 x축)
abline(res) # 회귀선 그리기 (y = b0 + b1x) y = 종속변수(x값에 따라 변함), b0 = 절편, b1 = 기울기, x = 독립변수
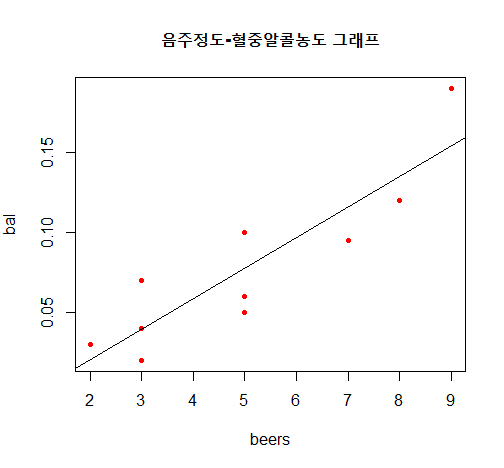
cor(beers,bal) # 상관계수 계산 : 0.8882323 -> 1또는 -1에 가깝기 때문에 상관성이 높다
피어슨 상관계수와 스피어만 상관계수 비교
피어슨 상관계수
개념
-> 등간척도, 비율척도로 측정된 두 변수들의 상관관계
특징
-> 연속형 변수, 정규성 가정 대부분 많이 사용 선형적 상관관계
스피어만 상관계수 ('ㅅ'자가 많이 들어감)
개념
-> 서열척도인 두 변수들이 상관관계
특징
-> 순서형 변수, 비모수적 방법 순위를 기준으로 상관관계 측정 비선형적 상관관계도 나타냄
연습문제
1) 다음은 직장인 10명의 수입과 교육받은 기간을 조사한 자료이다. 산점도와 상관계수를 구하고, 수입과 교육기간 사이에 어떤 상관관계가 있는지 설명하시오. (데이터프레임 X, 회귀식 X)
income <- c(121, 99, 41, 35, 40, 29, 35, 24, 50, 60)
period <- c(19, 20, 16, 16, 18, 12, 14, 12, 16, 17)
cor(income, period) # 0.7929108
분석 결과 : 상관계수가 0.7929108로 비교적 강한 양의 상관관계를 가진다. 따라서 수입 증가 시 교육기간 증가
2) 다음은 대학생 10명의 성적과 주당 TV 시청시간을 조사한 자료이다. 산점도와 상관계수를 구하고, 성적과 TV 시청시간 사이에 어떤 상관관계가 있는지 설명하시오. (데이터프레임 X, 회귀식 X)
score <- c(77.5, 60, 50, 95, 55, 85, 72.5, 80, 92.5, 87.5)
tv <- c(14, 10, 20, 7, 25, 9, 15, 13, 4, 21)
cor(score, tv) # -0.6283671
분석 결과 : 상관계수가 -0.6283671로 비교적 강한 음의 상관관계를 갖는다. 따라서 TV시청 시간 증가 시 성적 감소
선 그래프의 작성 (월별 지각생 통계)
month <- 1:12 # 자료 입력
late <- c(5, 8, 7, 9, 4, 6, 12, 13, 8, 6, 6, 4) # 자료 입력
plot(month, late, # x data, y data
main="지각생 통계", # 제목
type="l", # 그래프의 종류 선택(알파벳) l, b, s, o
lty=1, # 선의 종류(line type)
lwd=1, # 선의 굵기 선택
xlab="Month", # x축 레이블
ylab="Late cnt") # y축 레이블
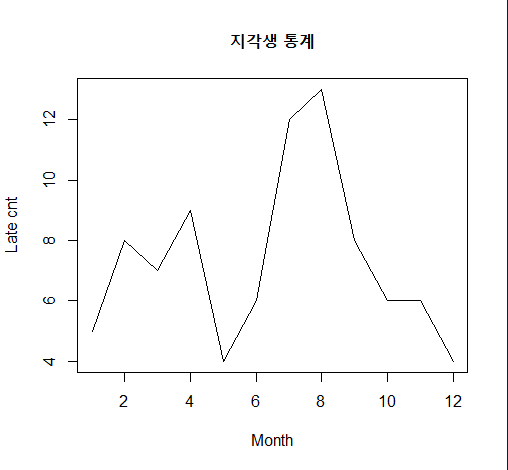
분석결과 : 5월 급감 7, 8월에 급증
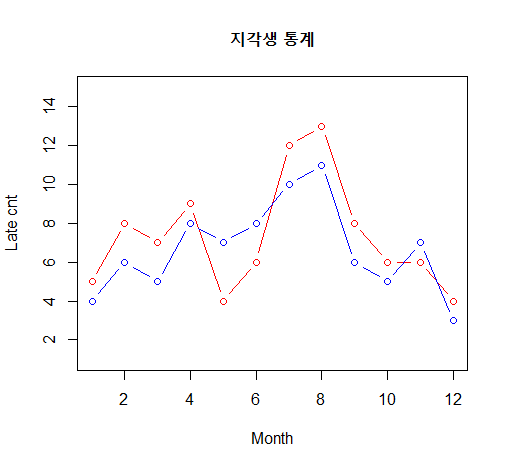
복수의 선 그래프 작성 (월별 지각생 통계)
month <- 1:12 # 자료 입력
late1 <- c(5, 8, 7, 9, 4, 6, 12, 13, 8, 6, 6, 4) # 자료 입력
late2 <- c(4, 6, 5, 8, 7, 8, 10, 11, 6, 5, 7, 3) # 자료 입력
plot(month, late1, # x data, y data
main="지각생 통계", # 제목
type="b", # 그래프의 종류 선택(알파벳) l, b, s, o
lty=1, # 선의 종류(line type)
col="red",
xlab="Month", # x축 레이블
ylab="Late cnt", # y축 레이블
ylim = c(1,15)) # y축 값의 (하한, 상한)
lines(month, late2, # x data, y data
type="b", # 선의 종류(line type)
col="blue") # 선의 색 선택
연습문제
1) R에서 제공하는 USAccDeaths 데이터셋은 1973년~1978년 사이의 사고 사망자 숫자를 월별로 나타낸 것이다. USAccDeaths 데이터셋에서 1973, 1975, 1977년의 월별 사망자 숫자를 선그래프로 작성하는데, 3개년도의 선의 색을 다르게 하시오.
str(USAccDeaths)
month <- 1:12
years.1973 <- window(USAccDeaths, 1973, c(1973, 12))
years.1975 <- window(USAccDeaths, 1975, c(1975, 12))
years.1977 <- window(USAccDeaths, 1977, c(1977, 12))
plot(month, years.1973,
main="USAccDeaths",
type="o",
lty=1,
col="red",
xlab="Month",
ylab="사망자 수",
ylim = c(6000, 12000)) # 안하면 데이터 짤림
lines(month, years.1975,
type="o",
col="blue")
lines(month, years.1977,
type="o",
col="orange")
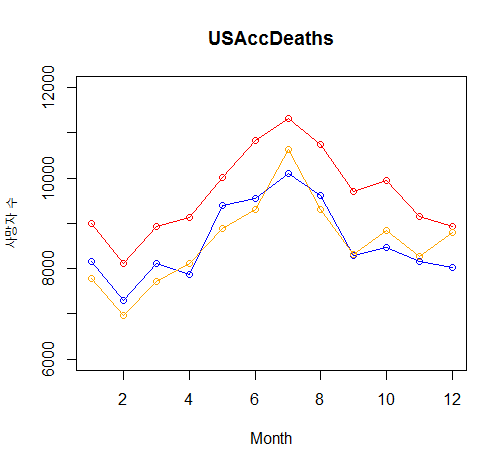
분석결과 : 7월에 사고가 제일 많다. -> why ?를 밝혀내면 더 좋을 것
'데이터 분석 > R' 카테고리의 다른 글
| 데이터 분석[R] - 6차시 (0) | 2021.07.02 |
|---|---|
| 데이터 분석[R] - 5차시 (0) | 2021.07.01 |
| 데이터 분석[R] - 3차시 (0) | 2021.06.29 |
| 데이터분석 [R] - 2차시 (0) | 2021.06.28 |
| 데이터 분석 [R] - 1차시 (0) | 2021.06.25 |



