본 글은 모두를 위한 R 데이터 분석 입문 책을 공부하면서 정리·요약한 내용입니다.
저자 : 오세종
출판 : 한빛아카데미
R의 장점으로 옳지 않은 것을 고르시오. - 2 -
① 오픈 소스이므로 사용자들이 만든 다양한 패키지들을 공유하여 사용 가능하므로 최신 알고리즘을 패키지를 통해 활용하기 쉽다.
② R은 사용자들이 많이 때문에 문제가 발생할 경우, 다양한 사용자들을 통해 문제를 해결하므로 다른 통계 패키지에 비해 유지보수가 신속하게 이루어진다.
③ 함수형 언어이기 때문에 다양한 프로그램을 통해 자동화 할 수 있다.
④ 무료로 이용할 수 있다
R에서 제공하는 데이터 가공, 처리를 위한 패키지의 설명으로 가장 부적절한 것은? - 1 -
① data.table 패키지는 데이터 프레임 처리함수인 ddply 함수를 제공한다.
② sqldf 패키지는 R에서 표준 SQL 명령을 실행하고 결과를 가져올 수 있다.
③ reshape 패키지는 melt와 cast를 이용하여 데이터를 재구성할 수 있다.
④ plyr 패키지는 데이터의 분리, 결합 등 필수적인 데이터 처리 기능을 제공한다.
데이터 분석 주제를 고르기 위한 Tip
- 네이버 데이터랩 검색어 트렌드
- 구글 트렌드
트렌드 검색 예시와 분석결과(지극히 주관적)

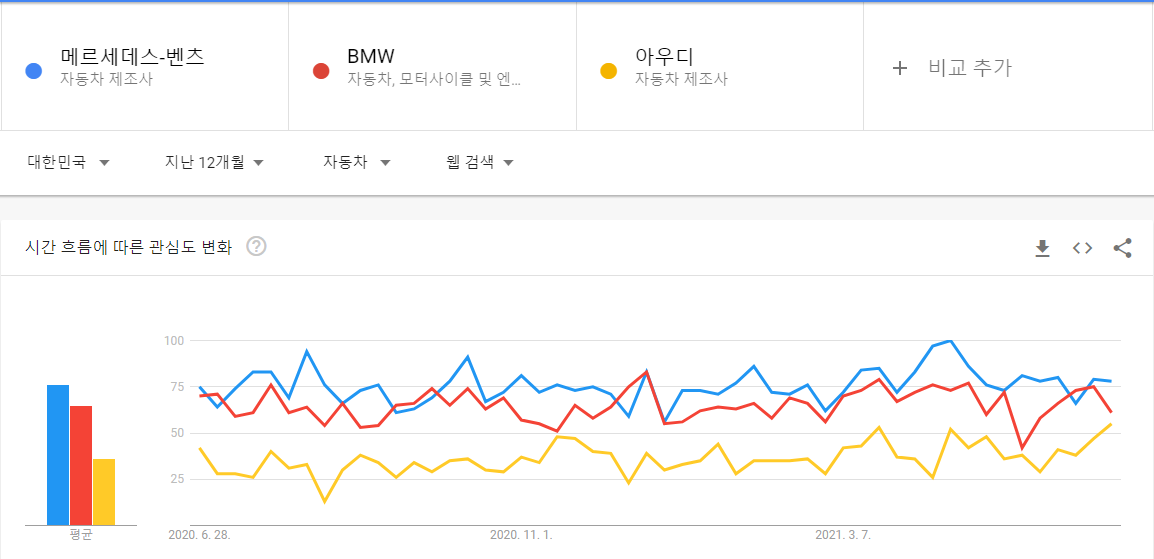
검색어 : 벤츠, BMW, 아우디
분석 결과(주관적) : 벤츠의 검색량이 많은 것을 확인할 수 있다. 이러한 결과에 대한 개인적인 분석은 다음과 같다.
1. 사람들이 제일 선호하는 브랜드가 벤츠이다.
2. 자동차의 성능이 제일 타 브랜드에 비해 좋다. -> 선호도가 높아질 수 있는 요인
기본적인 변수 사용법
<- : 변수에 값을 저장하는 연산자(Alt + -)
a <- 10 # 10을 변수 a에 저장
b <- 20 # 20을 변수 b에 저장
c <- a + b # 변수 a의 값과 변수 b의 값을 더하여 변수 c에 저장
print(c) # 변수 c의 값을 출력('c'만 입력해도 출력)
변수의 자료형
숫자형
a <- 10 # 숫자 10을 변수 a에 저장
문자형
name <- "Jake" # 문자열 Jake를 변수 name에 저장
논리형
bool <- TRUE # boolean TRUE의 값을 변수 bool에 저장
bool <- FALSE # boolean FALSE의 값을 변수 bool에 저장
특수 자료형
NULL # 정의되지 않음(자료형, 길이 : X)
NA # Not Available의 약자(결측값, 누락 데이터)
NaN # Not a Number의 약자
Inf, -Inf # 양의 무한대, 음의 무한대
다음 계산식의 코드를 작성하고 답을 구하시오.
1) 변수 a와 b에 각각 4와 5를 저장한 후 a+b의 결과를 c에 저장하고 c의 내용을 출력하라.
a <- 4
b <- 5
c = a + b
print(c)
2) 변수 pi에 3.14를 저장한 후 pi를 이용하여 반지름이 10, 12, 15인 원의 면적을 각각 구하라.
pi <- 3.14
rad1 = 10; rad2 = 12; rad3 = 15;
area1 = rad1^2 * pi
area2 = rad2^2 * pi
area3 = rad3^3 * pi
3) y=2*x^2+5x+10에 대해 x가 각각 6,8,10일 때 y의 값을 구하라.
x <- 6
y <- 2*x^2+5*x+10
x <- 8
y <- 2*x^2+5*x+10
x <- 10
y <- 2*x^2+5*x+10
벡터
R의 가장 기본이 되는 자료 객체로 1차원 데이터 구조
하나의 벡터에는 하나의 자료형만 입력 가능
- c() 함수 : 하나의 벡터에 여러 개의 값이 저장
- seq(시작값, 종료값, 간격) : 일정한 간격의 숫자로 이루어진 벡터를 작성
- rep(반복대상값, times=반복횟수) : 반복된 숫자로 이루어진 벡터를 작성
# 벡터 만들기1
x <- c(1,2,3,4,5) # 숫자형 벡터
y <- c("a", "b", "c") # 문자형 벡터
z <- c(T, T, F, T) # 논리형 벡터
x # x 출력
y # y 출력
z # z 출력
v1 <- 50:90 # 50에서 90으로 구성된 벡터 입력
v2 <- c(1,2,5,50:90) # 1, 2, 5, 50에서 90으로 구성된 벡터 입력
v1 # v1 출력
v2 # v2 출력
sum(v1) # v1의 합계를 구함
mean(v2) # v2의 평균을 구함
# 벡터 만들기2
v3 <- seq(1, 101, 3) # 1에서 101까지 3씩 증가하는 벡터
v3
v4 <- seq(0.1, 1.0, 0.1) # 0.1에서 1.0까지 0.1씩 증가하는 벡터
v4
v5 <- rep(1, times=5) # 1을 5번 반복
v5
v6 <- rep(1:5, times=3) # 1에서 5까지 3번 반복
v6
v7 <- rep(c(1, 5, 9), times=3) # 1, 5, 9를 3번 반복
v7
다음 계산식의 코드를 작성하고 답을 구하시오. (벡터)
1) 95, 86, 47, 55, 68로 구성된 벡터 vc.1을 생성하고 vc.1의 내용을 출력하는 코드를 작성하시오.
vc.1 <- c(95, 86, 47, 55, 68)
vc.1
2) 100~200 사이의 짝수로 구성된 벡터 vc.2를 생성하고 vc.2의 내용을 출력하는 코드를 작성하시오. (seq 함수 사용)
vc.2 <- seq(100, 200, 2)
vc.2
3) 20개의 TRUE로 구성된 vc.3를 생성하고 vc.3의 내용을 출력하는 코드를 작성하시오. (rep 함수 사용)
vc.3 <- rep(T, times=20)
vc.3
행렬
- 동일한 형태로 구성된 2차원 데이터 구조
- 행과 열로 이루어짐
- 행렬을 만드는 방법 3가지 : matrix(), cbind(), rbind()
# 행렬 만들기1
z <- matrix(1:20, nrow=4, ncol=5) # 1에서 20까지 4행 5열에 저장 (열방향)
z
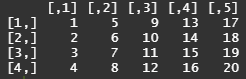
z2 <- matrix(1:20, nrow=4, ncol=5, byrow=T) # 행 방향으로 채우기 (byrow -> 행방향)
z2

# 행렬 만들기2
x <- 1:4 # 벡터 x 생성
y <- 5:8 # 벡터 y 생성
m1 <- cbind(x, y) # x와 y를 열 방향으로 결합하여 매트릭스 생성 (column bind)
m1

m2 <- rbind(x, y) # x와 y를 행 방향으로 결합하여 매트릭스 생성 (row bind)
m2

데이터 프레임
- 데이터베이스에서 테이블과 유사한 데이터 객체
- 각 열들이 서로 다른 형태의 객체를 가질 수 있음
- 데이터 프레임 만드는 방법 : data.frame()
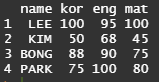
# 데이터프레임 만들기
name <- c("LEE", "KIM", "BONG", "PARK")
kor <- c(100, 50, 88, 75)
eng <- c(95, 68, 90, 100)
mat <- c(100, 45, 75, 80)
data.frame(name, kor, eng, mat) # name, kor, eng, mat로 데이터프레임 생성
원하는 형태로 iris 데이터 출력하기
str(iris)
iris
iris[, c(1:2)] # 1, 2열의 모든 데이터
iris[, c(1, 3, 5)] # 1, 3, 5열의 모든 데이터
iris[, c("Sepal.Length", "Species")] # 1, 5열의 모든 데이터
iris[1:5, ] # 1 ~ 5행의 모든 데이터
iris[1:5, c(1,3)] # 1 ~ 5행의 데이터 중 1, 3열의 데이터
리스트
- 서로 다른 유형의 데이터 구조 결합
- 리스트 만드는 방법 : list()
# 리스트 만들기
v <- c(1:6) # 벡터 생성
m <- matrix(c(1:12), nrow=3) # 행렬 생성
mylist <- list(v, m) # 리스트 생성
mylist # 리스트에 저장된 내용 모두 출력

mylist[[1]] # 리스트의 첫번째 값을 출력

mylist[[2]] # 리스트의 두번째 값을 출력
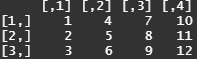
각 문제를 수행하기 위한 코드를 작성하시오. (데이터 프레임, 출력 형태)

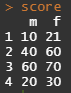
1) 위와 같은 내용의 데이터 프레임 score를 생성하시오.
m <- c(10, 40, 60, 20)
f <- c(21, 60, 70, 30)
score <- data.frame(m, f)
score
2) score의 열 이름을 각각 male, female로 바꾸시오.
colnames(score) <- c('male', 'female')
score

3) 2행에 있는 모든 값을 출력하시오.
score[2, ]

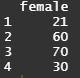
4) female의 모든 값을 출력하시오.
score[-1]
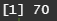
5) 3행 2열의 값을 출력하시오.
score[3, 2]
파일 형식 변환
- 엑셀 파일에 테이블 형태의 데이터가 저장되어 있는 경우를 가정
- 엑셀 파일을 .csv 형태로 변환하여 저장 후 R에서 .csv 파일을 읽음
- 읽어온 파일은 데이터 프레임 형태로 저장됨
# 파일 데이터 읽기
setwd("C:/Source") # 작업 폴더 지정
air <- read.csv("airquality.csv", header=T) # .csv파일 읽기 (열이름=T)
head(air)
# 파일 데이터 쓰기
my.iris <- subset(iris, Species == "setosa") # setosa 품종 데이터만 추출
write.csv(my.iris, "my_iris.csv", row.names=F) # .csv파일에 저장하기 (행번호=F)
각 문제를 수행하기 위한 코드를 작성하시오. (파일 형식 변환)
1) R에서 제공하는 state.x77 데이터셋을 data.frame 함수를 이용하여 데이터 프레임(이름 : st)로 변경하고 확인하시오.
st <- data.frame(state.x77)
str(st)
2) st 데이터셋에서 수입(Income)이 5,000 이상인 주의 데이터를 rich_state.csv 에 저장하시오.
setwd("C:/Source")
rich_state <- subset(st, Income >= 5000)
write.csv(rich_state, "rich_state.csv", row.names=F)
3) (1)에서 만든 rich_state.csv 파일을 읽어서 ds 변수에 저장한 후 ds의 내용을 출력하시오.
setwd("C:/Source")
ds <- read.csv("rich_state.csv", header=T)
ds
'데이터 분석 > R' 카테고리의 다른 글
| 데이터 분석[R] - 6차시 (0) | 2021.07.02 |
|---|---|
| 데이터 분석[R] - 5차시 (0) | 2021.07.01 |
| 데이터분석[R] - 4차시 (0) | 2021.06.30 |
| 데이터 분석[R] - 3차시 (0) | 2021.06.29 |
| 데이터 분석 [R] - 1차시 (0) | 2021.06.25 |



