감정 사전
감정을 나타낸 단어와 감정의 강도를 표현한 숫자로 구성됨
ex) 만족스럽다 +2
예쁘고 +2
좋아서 +2
나쁘고 -2
비싸다 -2
감정 점수 부여
디자인 예쁘고 마감도 좋아서 만족스럽다 => 합산 : +6
디자인은 만족스럽다. 그런데 마감이 나쁘고 가격도 비싸다 => 합산 : -2
간단한 문장을 감정 사전을 이용하여 분석
# 사용되는 패키지 활성화
library(stringr)
library(dplyr)
library(tidytext)
library(KoNLP)
library(ggplot2)
library(wordcloud2)
library(readr)
library(textclean)
setwd("작업 경로명") # 작업 경로 설정
dic <- read_csv("knu_sentiment_lexicon.csv") # 감정사전 csv파일 읽어오기
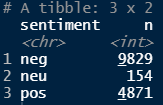
# 긍정, 중립, 부정 단어의 개수 파악
dic %>% mutate(sentiment = ifelse(polarity >= 1, "pos",
ifelse(polarity <= -1, "neg", "neu"))) %>%
count(sentiment)
# 분석할 문장 생성하기
df <- tibble(sentence = c("디자인 예쁘고 마감도 좋아서 만족스럽다.",
"디자인은 만족스럽다. 그런데 마감이 나쁘고 가격도 비싸다."))
df

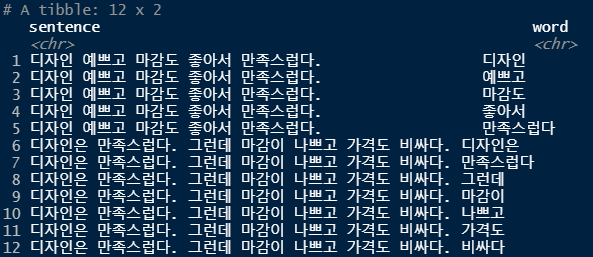
# 문장을 공백을 기준으로 토큰화(단어 토큰화)
df <- df %>%
unnest_tokens(input=sentence, output=word, token="words", drop=F) # 기존 sentence열을 나두고 word열을 추가
df
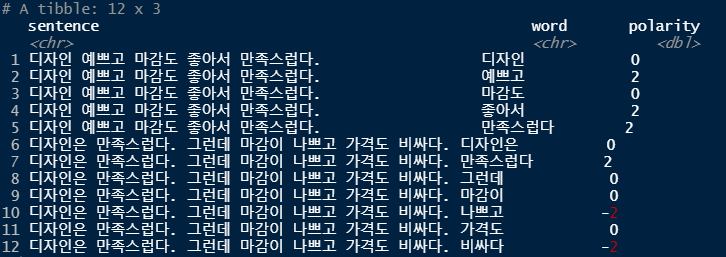
# 감정사전을 이용해 토큰화한 각단어의 점수 구하기
df <- df %>%
left_join(dic, by="word") %>%
mutate(polarity=ifelse(is.na(polarity), 0, polarity))
df
# 문장의 감정점수를 계산하기
df <- df %>%
group_by(sentence) %>%
summarise(score = sum(polarity))
df

# 기생충 댓글을 감정 사전을 이용하여 분석
setwd("작업 경로명") # 작업 경로 설정
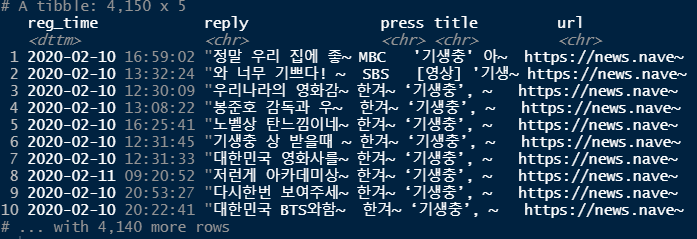
raw_news_comment <- read_csv("news_comment_parasite.csv") # 댓글 csv파일 읽어오기
raw_news_comment
news_comment <- raw_news_comment %>%
mutate(id=row_number(), # 행 번호 추가
reply = str_squish(replace_html(reply))) # reply안에 html tag가 존재시 공백으로 치환
news_comment
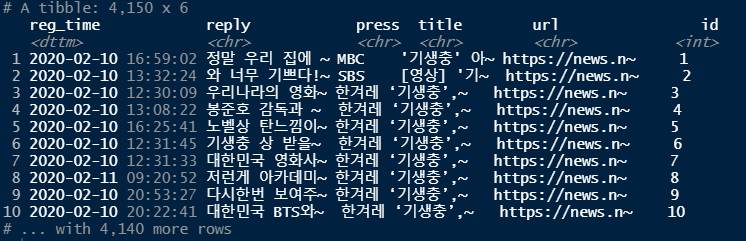
word_comment <- news_comment %>%
unnest_tokens(input=reply,
output=word,
token="words",
drop = F)
word_comment
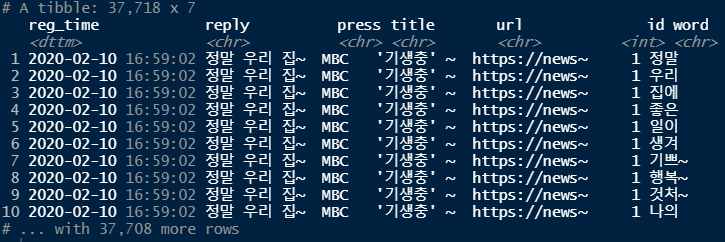
# 단어 추출 및 단어에 따른 감정 점수 부여하기
word_comment <- word_comment %>%
left_join(dic, by="word") %>%
mutate(polarity = ifelse(is.na(polarity), 0, polarity))
word_comment
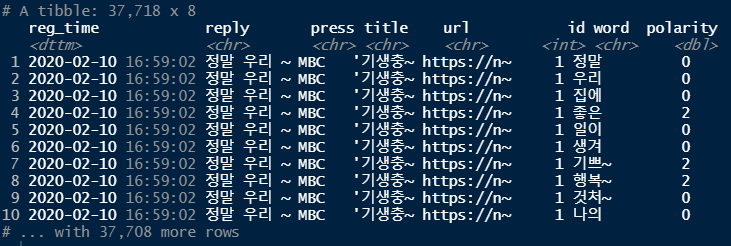
word_comment <- word_comment %>%
mutate(sentiment = ifelse(polarity >= 1, "pos",
ifelse(polarity <= -1, "neg", "neu")))
word_comment %>% select(word, sentiment, polarity)
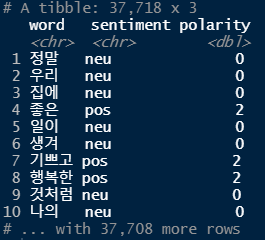
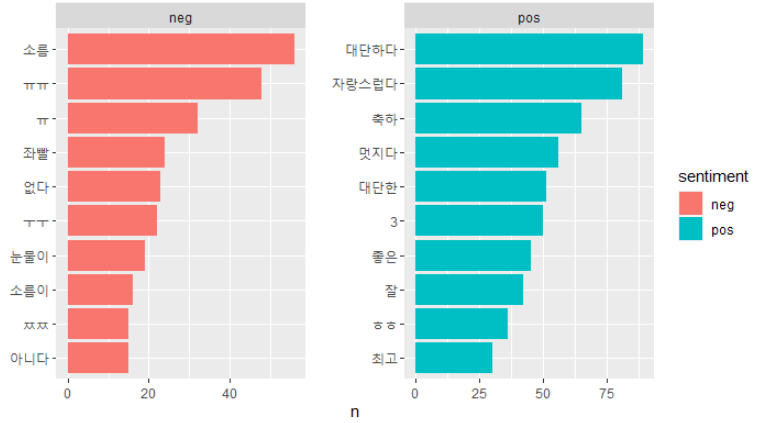
# 가장 많이 사용된 긍정, 부정 단어 10개씩 추출
top10 <- word_comment %>%
filter(sentiment != "neu") %>%
count(sentiment, word) %>%
group_by(sentiment) %>%
slice_max(n, n=10, with_ties = F)
ggplot(top10, aes(x=reorder(word, n), y=n, fill=sentiment)) +
geom_col() +
coord_flip() +
facet_wrap(~sentiment, scales = "free") +
scale_x_reordered() +
labs(x = NULL)
'데이터 분석 > R' 카테고리의 다른 글
| 데이터 분석[R] - 14차시 (0) | 2021.07.14 |
|---|---|
| 데이터 분석[R] - 13차시 (0) | 2021.07.13 |
| 데이터 분석[R] - 12차시 (0) | 2021.07.12 |
| 데이터 분석[R] - 11차시 (0) | 2021.07.09 |
| 데이터 분석[R] - 10차시 (0) | 2021.07.08 |



