본 글은 모두를 위한 R 데이터 분석 입문 책을 공부하면서 정리·요약한 내용입니다.
저자 : 오세종
출판 : 한빛아카데미
1. - 1 -
2. - 1 -
3. - 1 -
4. 최소제곱
복습
로지스틱 회귀(logistic regression) : 회귀모델에서 종속변수의 값의 형태가 연속형 숫자가 아닌 범주형 값인 경우를 다루기 위해서 만들어진 통계적 방법
주어진 데이터로부터 어떤 범주를 예측하는 분야를 회귀와 구분하여 분류(classification)라고 함
R에서 로지스틱 회귀 모델은 glm() 함수 이용
iris.new <- iris
iris.new$Species <- as.integer(iris.new$Species) # 범주형 자료를 정수로 변환
head(iris.new)
mod.iris <- glm(Species ~., data= iris.new) # 로지스틱 회귀모델 도출
summary(mod.iris) # 회귀모델의 상세 내용 확인
test <- iris[,1:4] # 예측 대상 데이터 준비
pred <- predict(mod.iris, test) # 모델을 이용한 예측
pred <- round(pred,0)
pred # 예측 결과 출력
answer <- as.integer(iris$Species) # 실제 품종 정보
pred == answer # 예측 품종과 실제 품종이 같은지 비교
acc <- mean(pred == answer) # 예측 정확도 계산
acc # 예측 정확도 출력
워드 클라우드의 개념
- 워드클라우드(word cloud)는 문자형 데이터를 분석하는 대표적인 방법으로, 대상 데이터에서 단어(주로 명사)를 추출하고 단어들의 출현 빈도수를 계산하여 시각화하는 기능
- 출현 빈도수가 높은 단어는 그만큼 중요하거나 관심도가 높다는 것을 의미
워드 클라우드 실습
install.packages("dplyr") # 데이터 처리에 특화된 패키지
install.packages("readr") # 데이터를 쉽게 읽을 수 있는 패키지
install.packages("tidytext") # 데이터를 깔끔하게 정리하는 패키지
install.packages("ggplot2") # 데이터 시각화 패키지
install.packages("wordcloud2") # 워드 클라우드 작성 패키지
library(dplyr)
library(readr)
library(tidytext)
library(ggplot2)
library(wordcloud2)
setwd("작업 경로") # 작업 경로 변경
f <- read_file("trump.txt") # 텍스트 파일을 하나의 문자열로 읽음
trump <- data_frame(f) # 데이터 프레임 작성
# 문자열을 단어 단위로 토큰화
tidy_trump <- trump %>% unnest_tokens(word,f)
# 불용어 제거
tidy_trump <- tidy_trump %>% anti_join(stop_words)
# 빈도수 내림차순으로 정렬
wordcount <- sort(table(tidy_trump),decreasing=T)
# 2회 이상 나온 단어
wordcount <- wordcount[wordcount > 2]
# 워드 클라우드 작성
wordcloud2(wordcount)

KoNLP를 이용한 한국어 텍스트 마이닝
- KoNLP는 한국어를 전용으로 처리하는 텍스트 마이닝 라이브러리
- SystemDic, SejongDic, NIADic이라는 세 종류의 사전을 지원함
- 사전과 관련된 명령어를 실행하면 사전의 크기, 즉 사전에 담긴 단어의 수를 알 수있음
사전과 관련된 명령어는 다음과 같음
useSystemDic(), useSejongDic(), useNIADic()
한글 형태소 분석 예제
useSejongDic()
s="너에게 묻는다 연탄재 함부로 발로 차지 마라 너는 누구에게 한번이라도 뜨거운 사람이었느냐"
extractNoun(s)

wordcloud2 (사랑을 했다 노래가사)
1. 패키지 설치
install.packages("KoNLP") # 한국어의 형태소 분석을 위한 패키지
install.packages("wordcloud2")
library(KoNLP)
library(wordcloud2)
useSejongDic() # 세종 한글사전 로딩
2. 데이터 불러오기
setwd("작업경로") # 작업 경로 변경
f <- file("word.txt")
txtLines <- readLines(f) # 파일을 한 줄씩 읽어서 저장
txtLines
3. 한글 명사만 추출
word <- unlist(sapply(txtLines, extractNoun, USE.NAMES=F))
word
word <- Filter(function(x) {nchar(x)>=2}, word) # 두 글자 이상만 추출
wordcount <- sort(table(word),decreasing=T)
4. 워드클라우드2
wordcloud2(wordcount)

wordcloud2(wordcount,size=0.5,shape='star')

wordcloud2(wordcount,size=0.5,shape='star',col='random-dark')

위키피디아 워드클라우드
install.packages('XML')
library(XML)
t <- readLines('https://ko.wikipedia.org/wiki/%EB%B9%85_%EB%8D%B0%EC%9D%B4%ED%84%B0')
d <- htmlParse(t, asText=TRUE) # t로부터 태그를 제거한 문서를 만듦
clean_doc <- xpathSApply(d, "//p", xmlValue) # p 태그 내의 텍스트를 추출
useSejongDic()
nouns <- extractNoun(clean_doc)
mnous <- unlist(nouns)
mnous_freq <- table(mnous)
v <- sort(mnous_freq, decreasing = TRUE)
wordcloud2(v)

v1 <- v[1:100]
wordcloud2(v1)

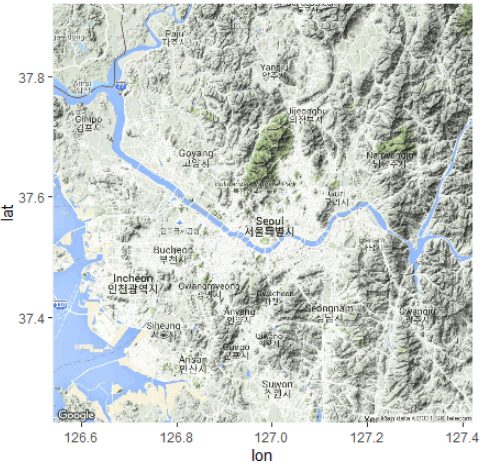
구글맵을 이용한 서울시 종로구 근방의 지도 보기
install.packages('ggmap')
library(ggmap)
register_google(key='자신의 API 키') # 구글키 등록
gc <- geocode(enc2utf8("종로구")) # 지점의 경도 위도
gc
cen <- as.numeric(gc) # 경도 위도를 숫자로
cen
map <- get_googlemap(center=cen) # 지도 생성
ggmap(map) # 지도 화면에 보이기
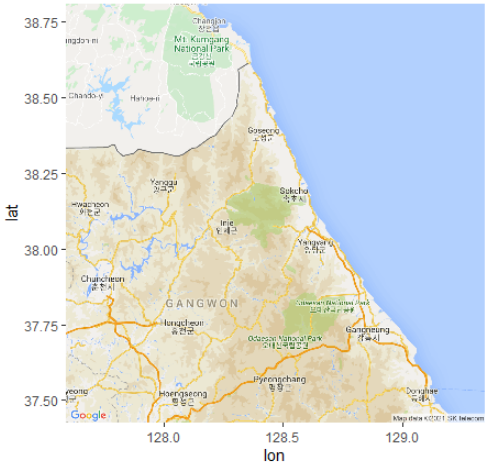
설악산 근방의 지도 보기
gc <- geocode(enc2utf8("설악산")) # 지점의 경도 위도
cen <- as.numeric(gc) # 경도 위도를 숫자로
map <- get_googlemap(center=cen, # 지도의 중심점 좌표(경도, 위도)
zoom=9, # 지도 확대 정도(3(대륙)~21(빌딩), 기본값은 10(도시))
size=c(640,640), # 지도의 픽셀 크기(최댓값 : 640x640)
maptype="roadmap") # 지도의 유형(terrian(기본값), roadmap, satellite, hybrid)
ggmap(map) # 지도 화면에 보이기
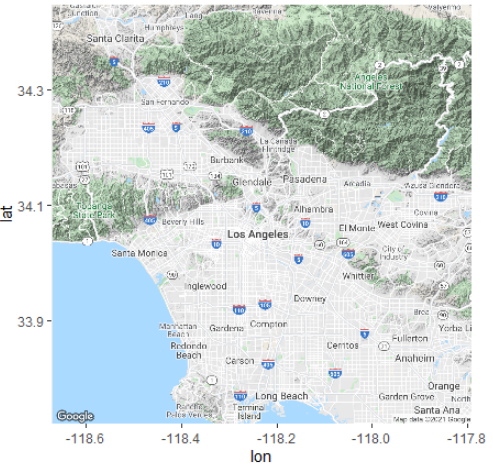
경도와 위도 값을 입력하여 지도 보기
cen <- c(-118.233248, 34.085015)
map <- get_googlemap(center=cen) # 지도 생성
ggmap(map) # 지도 화면에 보이기
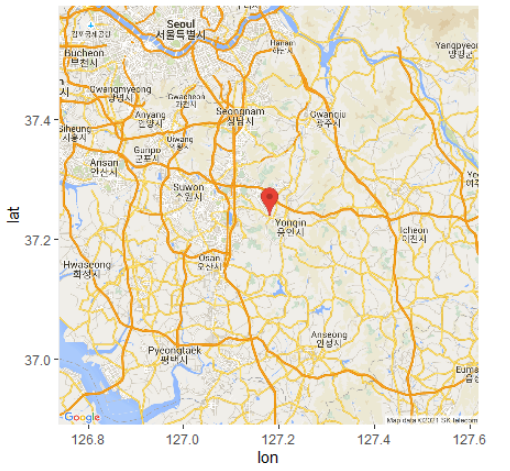
지도의 중심 지점에 마커 표시
gc <- geocode(enc2utf8("용인")) # 지점의 경도와 위도
cen <- as.numeric(gc) # 경도와 위도를 숫자로
map <- get_googlemap(center=cen, # 지도의 중심
maptyp="roadmap", # 지도의 형태
marker=gc) # 마커의 위치
ggmap(map) # 지도 화면에 보이기
지도의 여러 지점에 마커와 텍스트 표시
names <- c("용두암","성산일출봉","정방폭포",
"중문관광단지","한라산1100고지","차귀도")
addr <- c("제주시 용두암길 15",
"서귀포시 성산읍 성산리",
"서귀포시 동홍동 299-3",
"서귀포시 중문동 2624-1",
"서귀포시 색달동 산1-2",
"제주시 한경면 고산리 125")
gc <- geocode(enc2utf8(addr)) #주소를 경도와 위도로 변환
gc
# 관광지 명칭과 좌표값으로 데이터프레임 생성
df <- data.frame(name=names,
lon=gc$lon,
lat=gc$lat)
df
cen <- c(mean(df$lon),mean(df$lat)) # 지도의 중심점
map <- get_googlemap(center=cen, # 지도 가져오기
maptype="roadmap", # 지도의 형태
zoom=10, # 지도의 확대 크기
size=c(640,640), # 지도의 크기
marker=gc) # 마커의 위치
ggmap(map) # 지도와 마커 화면에 보이기
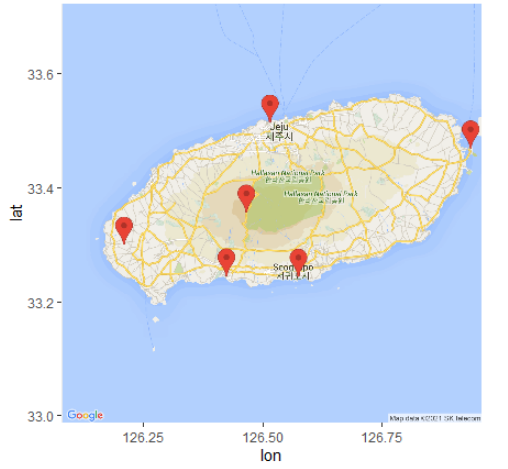
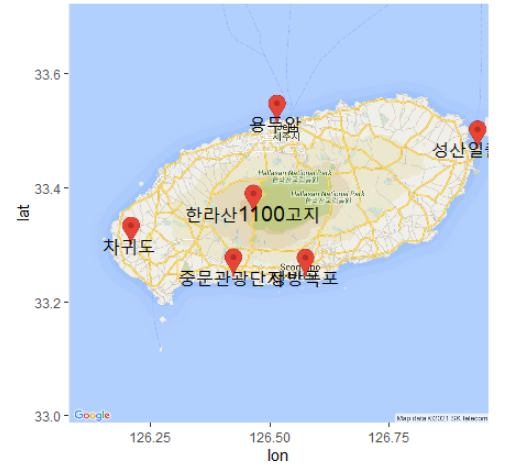
# 명소 이름 지도 위에 표시하기
gmap <- ggmap(map)
gmap+geom_text(data=df, # 지도 위에 텍스트 표시
aes(x=lon,y=lat), # 텍스트 위치(관광지 좌표)
size=5, # 텍스트 크기
label=df$name) # 텍스트 내용
지도 위에 데이터 표시
- 구글맵 위에는 마커나 텍스트뿐만 아니라 ggplot 패키지를 이용하여 원과 같은 도형도 표시할 수 있음
- ggmap 패키지에서 제공하는 wind 데이터셋을 이용하여 지도 위에 데이터를 표현하는 방법을 실습
- wind 데이터셋은 미국 루이지애나주 부근의 여러 지점에서 측정한 바람에 대한 정보를 담고 있음
# 데이터 준비
sp <- sample(1:nrow(wind),50) # 50개 데이터 샘플링
df <- wind[sp,]
head(df)
cen <- c(mean(df$lon), mean(df$lat)) # 지도의 중심점 계산
gc <- data.frame(lon=df$lon, lat= df$lat) # 측정위치 좌표값 데이터
head(gc)
# 측정 위치에 마커 표시하기
map <- get_googlemap(center=cen,
maptype="roadmap",
zoom=6,
marker=gc)
ggmap(map)
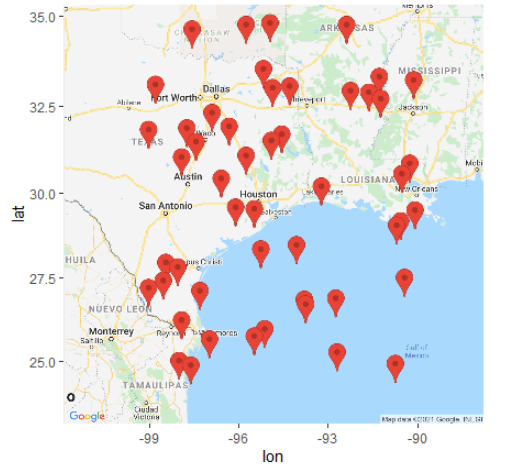
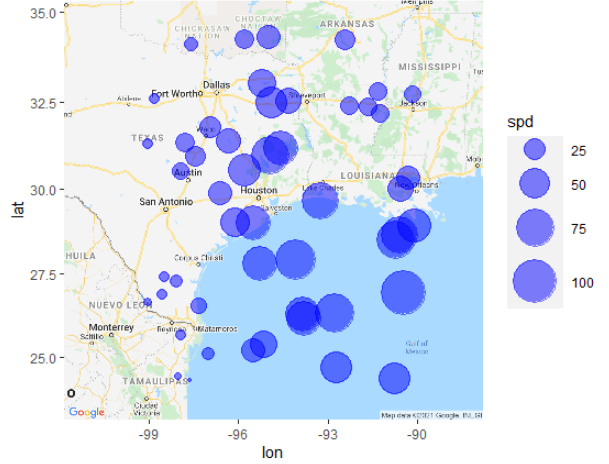
# 풍속을 원의 크기로 표시하기
map <- get_googlemap(center=cen, # 마커 없는 지도 가져오기
maptype="roadmap",
zoom=6)
gmap <- ggmap(map) # 지도를 저장
gmap+geom_point(data=df, # 풍속을 원의 크기로 표시
aes(x=lon,y=lat,size=spd),
alpha=0.5,
col="blue") +
scale_size_continuous(range = c(1, 14)) # 원의 크기 조절
'데이터 분석 > R' 카테고리의 다른 글
| 데이터 분석[R] - 14차시 (0) | 2021.07.14 |
|---|---|
| 데이터 분석[R] - 13차시 (0) | 2021.07.13 |
| 데이터 분석[R] - 11차시 (0) | 2021.07.09 |
| 데이터 분석[R] - 10차시 (0) | 2021.07.08 |
| 데이터 분석[R] - 9 차시 (0) | 2021.07.07 |



