본 글은 모두를 위한 R 데이터 분석 입문 책을 공부하면서 정리·요약한 내용입니다.
저자 : 오세종
출판 : 한빛아카데미
1. - 2 -
2. - 3 -
3. - 3 -
복습
idx <- sample(1:nrow(iris), size=50, replace=FALSE)
iris.50 <- iris[idx,]
dim(iris.50)
head(iris.50)
agg <- aggregate(iris[,-5], by=list(품종=iris$Species), FUN=mean)
agg
x <- data.frame(name=c("a", "b", "c"), math=c(90, 80, 40))
y <- data.frame(sname=c("a", "b", "d"), korean=c(75,60, 90))
x
y
merge(x, y, by.x=c("name"), by.y=c("sname"))
데이터 시각화의 중요성
데이터 시각화(data visualization) : 숫자 형태의 데이터를 그래프나 그림등의 형태로 표현하는 과정
데이터 분석 과정에서 중요한 기술 중의 하나
데이터를 시각화 하면 데이터가 담고 있는 정보나 의미를 보다 쉽게 파악 가능
트리맵
사각타일의 형태로 시각화, 각 타일의 크기와 색깔로 데이터의 크기를 나타냄
각각의 타일은 계층 구조가 있기 때문에 데이터에 존재하는 계층 구조도 표현 가능
install.packages("treemap") # treemap 패키지 설치
library(treemap) # 패키지 활성화
data(GNI2014) # GNI2014 데이터셋 로딩
? GNI2014 # 2014년 1인당 국민총소득
str(GNI2014)
treemap(GNI2014,
index=c("continent", "iso3"), # 계층구조 설정(대륙-국가명)
vSize="population", # 타일의 크기 - 인구 수
vColor="GNI", # 타일의 컬러 - 국민 총소득
type="value", # 타일 컬러링 방법
bg.labels="yellow", # 레이블 배경색
title="World's GNI") # 트리맵 제목
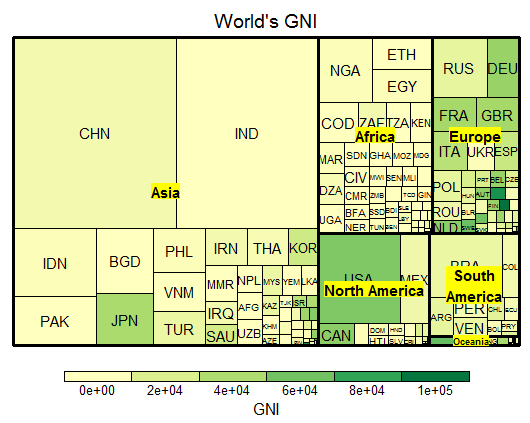
분석 결과
가장 인구가 많은 나라는? 중국, 인도
아시아에서 소득이 높은 나라는? 일본
state.x77 데이터셋으로 트리맵 작성하기
library(treemap) # treemap 패키지 불러오기
st <- data.frame(state.x77) # 매트릭스를 데이터프레임으로 변환
st <- data.frame(st, stname=rownames(st)) # 주 이름 열 stname을 추가
treemap(st,
index=c("stname"), # 타일에 주 이름 표기
vSize="Area", # 타일의 크기
vColor="Income", # 타일의 컬러
type="value", # 타일 컬러링 방법
title="USA states area and income") # 트리맵의 제목
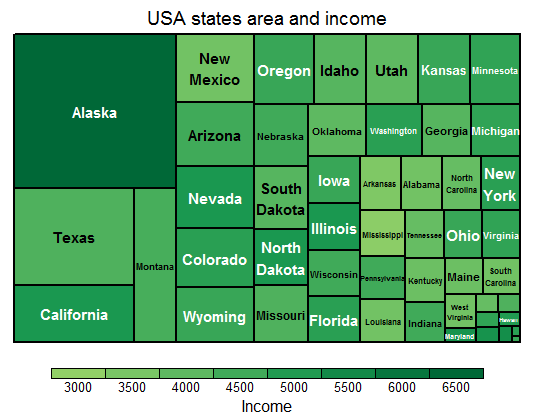
분석 결과
면적이 가장 넓은 주는? 알래스카
소득이 가장 높은 주는? 알래스카
버블차트
버블 차트(bubble chart) : 앞에서 배운 산점도 위에 버블의 크기로 정보를 표시하는 시각화 방법
산점도가 2개의 변수에 의한 위치 정보를 표시한다면, 버블 차트는 3개의 변수 정보(x축, y축, 크기)를 하나의 그래프에 표시
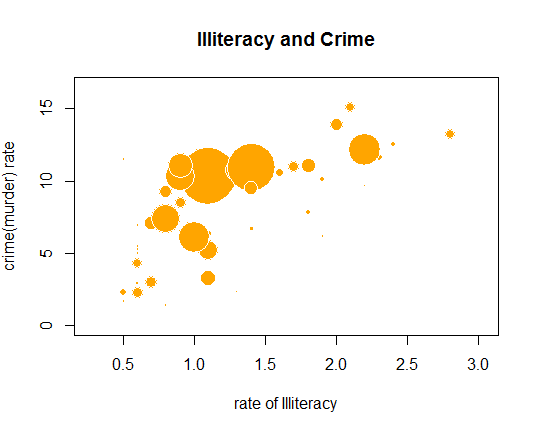
st <- data.frame(state.x77) # 매트릭스를 데이터프레임으로 변환
symbols(st$Illiteracy, st$Murder, # 원의 x, y 좌표의 열 - 문맹률, 범죄율
circles=st$Population, # 원의 반지름 열
inches=0.3, # 원의 크기 조절
fg="white", # 원의 테두리 색
bg="orange", # 원의 바탕색
lwd=1.5, # 원의 테두리선 두께
xlab="rate of Illiteracy", # x축에 대한 설명
ylab="crime(murder) rate", # y축에 대한 설명
main="Illiteracy and Crime") # 차트 제목
text(st$Illiteracy, st$Murder, # 텍스트가 출력될 x, y 좌표
rownames(st), # 출력할 텍스트
cex=0.6, # 폰트 크기
col="brown") # 폰트 컬러
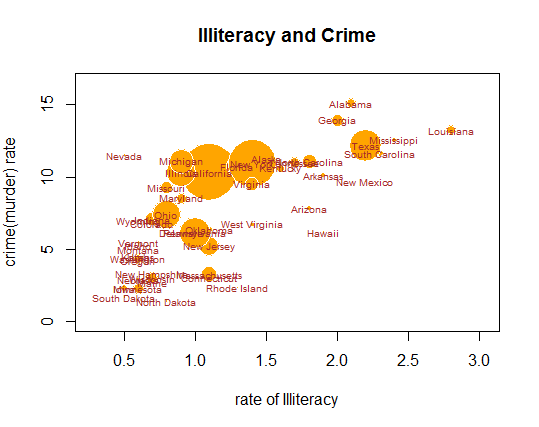
분석 결과
문맹률이 증가할 수록 범죄율이 증가하는 추세
인구수가 많을 수록 대체로 범죄율도 높음
모자이크 플롯
모자이크 플롯(mosic plot): 다중변수 범주형 데이터에 대해 각 변수의 그룹별 비율을 면적으로 표시하여 정보를 전달
head(mtcars)
mosaicplot(~gear+vs, data = mtcars, color=TRUE, # '~'다음의 변수가 x축 방향으로 표시되고, '+'다음의 변수가 y축 방향으로 표시됨
main="Gear and Vs")
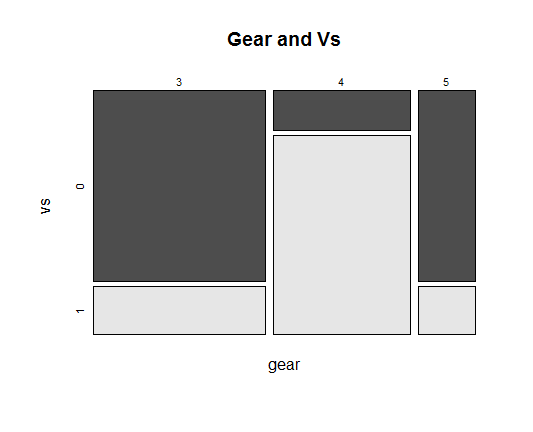
분석 결과
기어 개수 중 가장 높은 비율을 차지하는 것은? 3
기어 개수가 홀수인 경우 많은 엔진 타입은? 0
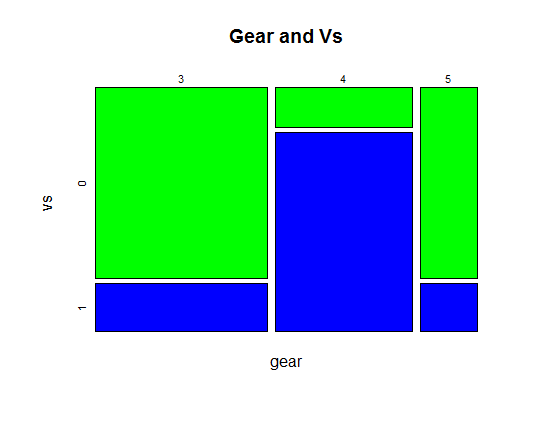
# 색깔 변경
mosaicplot(~gear+vs, data = mtcars, color=c("green", "blue"), # '~'다음의 변수가 x축 방향으로 표시되고, '+'다음의 변수가 y축 방향으로 표시됨
main="Gear and Vs")
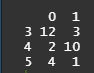
# 분할도 확인
tbl <- table(mtcars$gear, mtcars$vs)
tbl
연습문제
1) 미국 50개 주에 대해 각각의 주들이 지역구분별로 묶인 트리맵을 작성하시오. 또한, 타일의 면적은 HS.Grad(고등학교 졸업률), 타일의 색은 Murder(범죄률)로 나타내고, 각각의 타일에는 주의 이름을 표시하시오. 마지막으로 이 트리맵에서 관찰할 수 있는 것이 무엇인지 설명하시오.
us <- data.frame(state.x77, state.division)
us <- data.frame(us, state=rownames(us))
treemap(us,
index=c("state.division", "state"), # 계층구조 설정
vSize="HS.Grad", # 타일의 크기
vColor="Murder", # 타일의 컬러
type="value", # 타일 컬러링 방법
bg.labels="yellow", # 레이블의 배경색
title="US") # 트리맵 제목
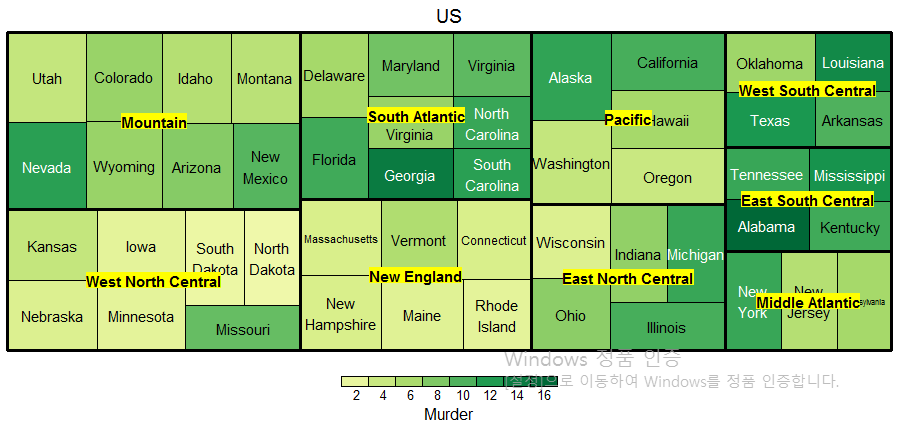
분석 결과
범죄율이 높은 주는? Albama
범죄율이 낮은 주는? North Dakota
범죄율과 졸업률과 관계는? 상관관계는 찾아보기 어려움
2) us 데이터셋에 대해 x축은 Income(소득), y축은 Illiteracy(문맹률), 원의 크기는 Population(인구수), 원의 색은 green(초록색), 원 내부에는 주의 이름을 표시한 버블차트를 작성하시오. 또한, 이 버블차트에서 관찰할 수 있는 것이 무엇인지 설명하시오.
symbols(us$Income, us$Illiteracy,
circles=us$Population,
inches=0.5,
fg="white",
bg="green",
lwd=1.5,
xlab="Income",
ylab="Illiteracy",
main="Income and Illiteracy")
text(us$Income, us$Illiteracy,
us$state,
cex=0.6,
col="brown")
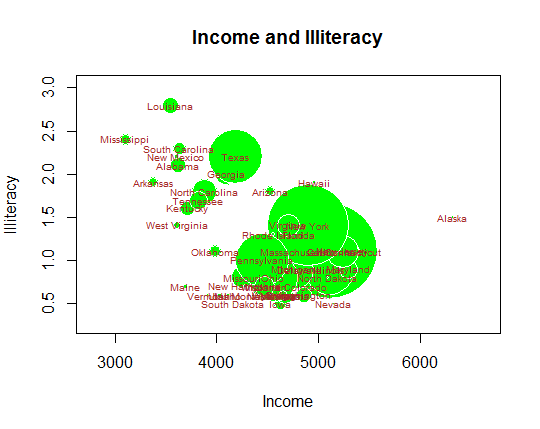
분석 결과
수입이 많은 주일수록 문맹률은 낮아짐
3) HairEyeColor 데이터셋에 대해 모자이크 플롯을 작성하고, 이 모자이크 플롯에서 관찰할 수 있는 것이 무엇인지 설명하시오.
HairEyeColor
mosaicplot(~Hair+Eye, data=HairEyeColor,
color=c("brown", "blue", "#ae9f80", "Green"),
main="Hair and Eye")
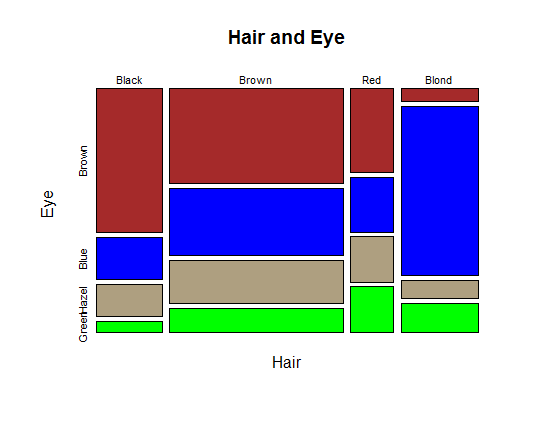
분석 결과
머리색은 brown인 사람이 제일 많고 red인 사람이 가장 적음
눈의 색은 brown인 사람이 제일 많고 green인 사람이 가장 적음
머리색이 blond인 경우 눈이 blue인 사람이 가장 많음
ggplot2 패키지
뉴질랜드의 통계학자 Hadley Wickham이 개발
복잡한 시각화 산출물을 단계별 접근법을 통해 생성
산점도, 상자그림, 시계열 그래프 등을 생성
ggplot 명령문의 기본 구조
1. 하나의 ggplot() 함수와 여러 개의 geom_xx() 함수들이 +로 연결되어 하나의 그래프를 완성
2. ggplot() 함수의 매개변수로 그래프를 작성할 때 사용할 데이터셋(data=xx)와 데이터셋 안에서 x축, y축으로 사용할 열 이름(aes(x=x1,y=x2))을 지정
3. 데이터를 이용하여 어떤 형태의 그래프를 그릴지를 geom_xx()를 통해 지정
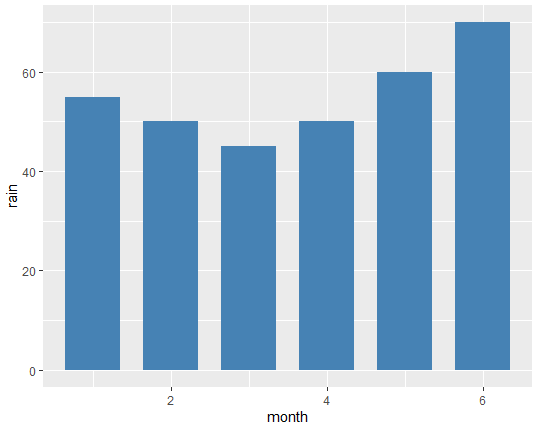
기본적인 막대그래프 작성하기(ggplot2)
library(ggplot2)
month <- c(1, 2, 3, 4, 5, 6)
rain <- c(55, 50, 45, 50, 60, 70)
df <- data.frame(month, rain) # 그래프를 작성할 대상 데이터
df
ggplot(df, aes(x=month, y=rain))+ # 그래프를 그릴 데이터 지정
geom_bar(stat="identity", # 막대의 높이는 y축에 해당하는 열의 값
width=0.7, # 막대의 폭 지정
fill="steelblue") # 막대의 색 지정
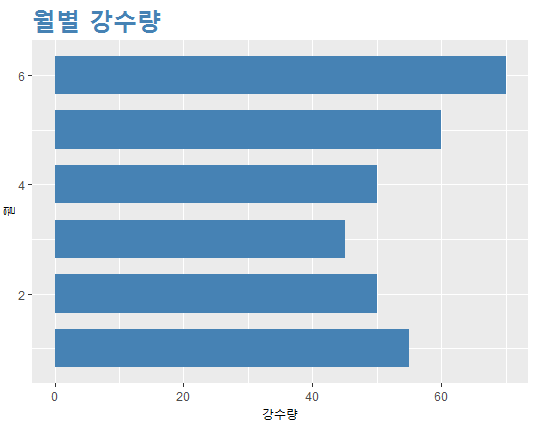
기본적인 막대그래프 꾸미기(ggplot2)
ggplot(df, aes(x=month, y=rain))+ # 그래프를 그릴 데이터 지정
geom_bar(stat="identity", # 막대 높이는 y축에 해당하는 열의 값
width=0.7, # 막대의 폭 지정
fill="steelblue")+ # 막대의 색 지정
ggtitle("월별 강수량")+ # 그래프의 제목 지정
theme(plot.title=element_text(size=25, face="bold",
colour="steelblue"))+
labs(x="월", y="강수량")+ # 그래프의 x, y축 레이블 지정
coord_flip() # 그래프를 가로 방향으로 출력
기본적인 히스토그램 작성하기(ggplot2)
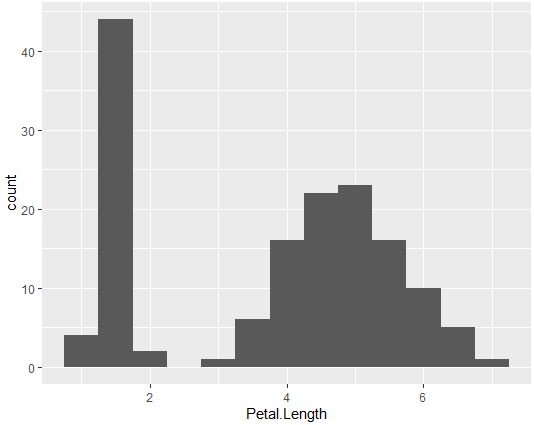
ggplot(iris, aes(x=Petal.Length))+ # 그래프를 그릴 데이터 지정
geom_histogram(binwidth=0.5) # 히스토그램 작성
그룹별 히스토그램 작성하기(ggplot2)
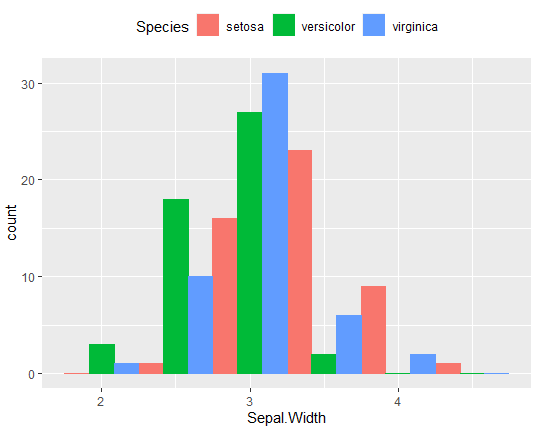
ggplot(iris, aes(x=Sepal.Width, fill=Species, color=Species))+
geom_histogram(binwidth=0.5, position="dodge")+
theme(legend.position="top")
기본적인 산점도 작성하기(ggplot2)
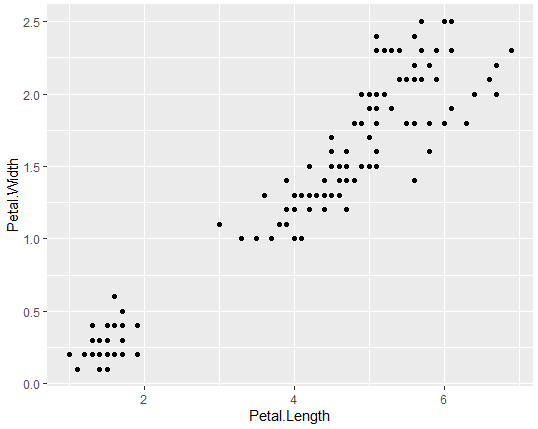
ggplot(data=iris, aes(x=Petal.Length, y=Petal.Width))+
geom_point()
그룹별 산점도 작성하기(ggplot2)
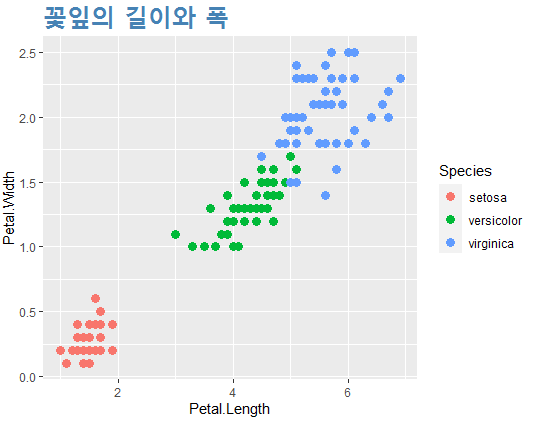
ggplot(data=iris, aes(x=Petal.Length, y=Petal.Width,
color=Species))+
geom_point(size=3)+
ggtitle("꽃잎의 길이와 폭")+
theme(plot.title=element_text(size=25, face="bold",
colour="steelblue"))
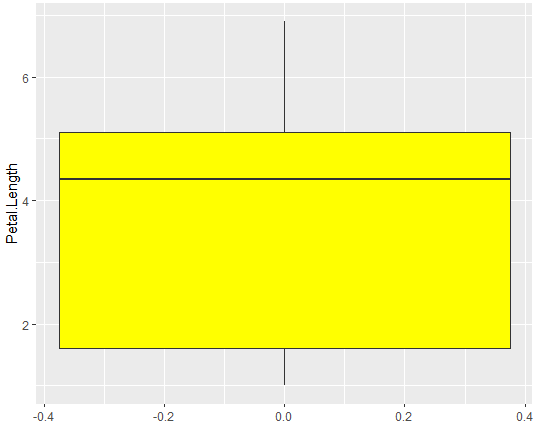
기본적인 상자그림 작성하기(ggplot2)
ggplot(data=iris, aes(y=Petal.Length))+
geom_boxplot(fill="yellow")
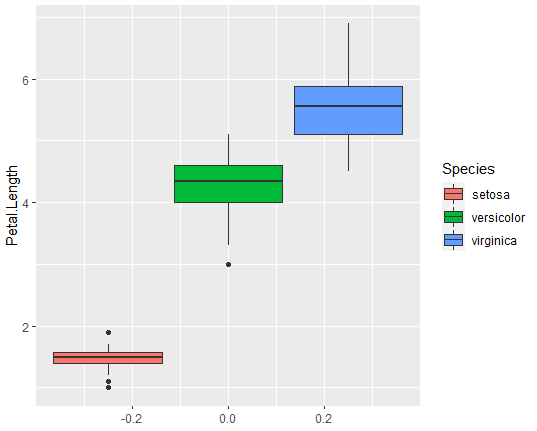
그룹별 상자그림 작성하기(ggplot2)
ggplot(data=iris, aes(y=Petal.Length, fill=Species))+
geom_boxplot()
'데이터 분석 > R' 카테고리의 다른 글
| 데이터 분석[R] - 10차시 (0) | 2021.07.08 |
|---|---|
| 데이터 분석[R] - 9 차시 (0) | 2021.07.07 |
| 데이터 분석[R] - 7차시 (0) | 2021.07.05 |
| 데이터 분석[R] - 6차시 (0) | 2021.07.02 |
| 데이터 분석[R] - 5차시 (0) | 2021.07.01 |



